In previous post we studied basic scenarios to apply:
With all these knowledge we are ready to create, step by step, a custom Hugo shortcode that renders a CSV into a table displaying even an image column.
A picture is worth a thousand words. We will create this cheatsheet for Age of Empires II (complete table here).
In the process we will cover:
- How to integrate data repositories in our Hugo project via Git submodules
- Generate dataset structures applying basic data preprocessing algorithms (import, filter, join,…) and tools
(
jq,sed,awk,pandas,…).
Normally one picks a code and sticks to it, for example Python via Jupyter Notebooks or R via RStudio.
But our data mining task is somehow simple enough to be accomplished with short shell and Python scripts while taking advantage of the power of Hugo shortcode template that we will code to render CSV tables and the images referenced in it.
Index - Click to expand 📜
Hugo layout for jumbo landscape elements
The tables to be rendered might expand horizontally much more than what would fit in a single page theme layout.
In my post concerning Hugo bundle pages we learned how to create a layout for a bundle page. Read Custom layouts for a leaf bundle. Following the same pattern applies.
Minimal layout
We create a very basic template in layouts/minimal/single.html.
# Copy single.html
newLayout="layouts/minimal/single.html"
mkdir -p "$(dirname "$newLayout")"
cp -v _vendor/github.com/zjedi/hugo-scroll/layouts/_default/single.html "$newLayout"
# Edit width
# sed -i 's/<article class="post page">/<article class="page">/g' "$newLayout"
sed -i 's|<article class="post page">|<article class="post page" style="width: 99%; max-width: 100%;">|g' "$newLayout"
In <article> we can remove the post in class-es (commented code line),
which is defined in Hugo Scroll theme assets/css/theme.scss,
because we want to use full width tables, not width: 80%; max-width: 700px;.
Instead, last code line applied the CSS herarchy, an inline style in <article>.
Also add a {{ .TableOfContents }} inbetween <h1> and {{ .Content }}.
sed -i '/<h1 class="post-title">{{ .Title }}<\/h1>/a\
<p>Index</p>\
{{ .TableOfContents }}' "$newLayout"
Create a leaf page to test the new layout.
# content/en/ not needed
hugo new aoe2_cheatsheet/index.md
# Open
$EDITOR content/en/aoe2_cheatsheet/index.md
Edit front matter and content:
1---
2title: 'AOE2 Cheatsheet'
3type: "minimal"
4---Test the minimal layout with a wide table like next.
| Name | Age | Score | Country | City | Nationality | University | Experience (years) |
|---|---|---|---|---|---|---|---|
| Maria | 30 | 95 | Spain | Madrid | Spanish | UNED | 3 |
| Daniel | 25 | 87 | Germany | Berlin | German | Hochschule Muenchen | 2.5 |
See it here.
The table is rendered as expected.
Note, a single page, instead of index.md, would be valid for this test.
Shortcodes
Lets create a Hugo shortcode that prints the local resources content of type CSV.
The template must eventually render a column as <img> too.
To achieve this we will progress little by little.
Get local resources
Code layouts/shortcodes/getresource-test-01.html to print local resources content.
{{ $path := .Get "path" }}
{{ $resource := .Page.Resources.GetMatch $path }}
{{ if $resource }}
<div class="resource-content">
<h4>Resource: {{ $resource.Name }}</h4>
{{ if eq $resource.MediaType.SubType "csv" }}
<pre>{{ $resource.Content }}</pre>
{{ else if eq $resource.MediaType.SubType "svg" }}
<div class="svg-container">{{ $resource.Content | safeHTML }}</div>
{{ else if eq $resource.MediaType.Type "image" }}
<img src="{{ $resource.RelPermalink }}" alt="{{ $resource.Name }}" loading="lazy">
{{ else }}
<pre>{{ $resource.Content }}</pre>
{{ end }}
</div>
{{ else }}
<div class="error">
<p>Resource not found in page bundle: {{ $path }}</p>
<p>Current page directory: {{ .Page.File.Dir }}</p>
<p>Available resources in this bundle:</p>
<ul>
{{ range .Page.Resources }}
<li>{{ .Name }} ({{ .MediaType }})</li>
{{ else }}
<li>No resources found in this page bundle</li>
{{ end }}
</ul>
</div>
{{ end }}
Get a sample CSV
dataDir="content/en/aoe2_cheatsheet/data/sample"
mkdir -p "$dataDir"
curl -o "$dataDir/iris.csv" https://www.timestored.com/data/sample/iris.csv
Append next to content/en/new aoe2_cheatsheet/index.md:
{{< getresource-test-01 path="data/sample/iris.csv" >}}
See it here. The content of this CSV is raw displayed.
Note. A single page would not work because the shortcode reads resources in our local bundle,
not in a global resource path like data/ or assests/.
The error message list the available resources in the bundle. Test it with:
{{< getresource-test-01 path="test-missing-file.csv" >}}
See it here.
It renders
Resource not found in page bundle: test-missing-file.csv
Current page directory: aoe2_cheatsheet/
Available resources in this bundle:
- data/sample/iris.csv (text/csv)
- [...]
Minimal table
We need to create a shortcode that accepts a CSV file-path as parameter.
Next is a good starting point. Book Hugo in Action, Parsing files for data:
We need to render this [
products.csv] as a table in the home page of the website. We can place products.csv in the root of thecontentfolder to make it a part of the branch bundle for the index page.
We create layouts/shortcodes/csv-to-table.html, to render a bundle resource CSV,
copying this template.
Courtesy of https://gitlab.nccr-automation.ch/docs/hugo-docsy.
template="layouts/shortcodes/csv-to-table.html"
URL="https://gitlab.nccr-automation.ch/docs/hugo-docsy/-/raw/main/layouts/shortcodes/csv-to-table.html"
wget -O "${template}" "${URL}"
Add to index.md next shortcode call. In later sections it’s explained how to generate that CSV file.
{{< csv-to-table path="data/sample/iris.csv" >}}
See it here.
Table that renders images
Copy the previous template and extend it.
layouts/shortcodes/csv-to-table-imgs.html must be coded to:
- Accept
img_path,img_field,img_formatandimg_field_rawparameters. - Render a project resources images.
Debugging it’s useful to display both the rendered image and the column that specifies it.
- When
img_field_raw="false": show only the rendered image column (without the originalimg_fieldcolumn) - When
img_field_raw="true"(default): show both
csv-to-table-imgs.html - Click to expand 📜
{{- /* csv-to-table-imgs.html */ -}}
{{- /* Converts a CSV file to an HTML table with images */ -}}
{{- $path := .Get "path" -}}
{{- $img_path := .Get "img_path" -}}
{{- $img_field := .Get "img_field" -}}
{{- $img_format := .Get "img_format" | default "png" -}}
{{- $img_field_raw := .Get "img_field_raw" | default "true" -}}
{{- $caption := .Get "caption" | default "" -}}
{{- $class := .Get "class" | default "" -}}
{{- $delimiter := .Get "delimiter" | default "," -}}
{{- $hasHeaderRow := .Get "hasHeaderRow" | default true -}}
{{- $id := .Get "id" | default (printf "csv-table-%d" .Ordinal) -}}
{{- /* Get the CSV resource from the page bundle */ -}}
{{- $resource := .Page.Resources.GetMatch $path -}}
{{- if not $resource -}}
<div class="error">
<p>CSV resource not found: {{ $path }}</p>
<p>Available resources in this bundle:</p>
<ul>
{{- range .Page.Resources -}}
<li>{{ .Name }} ({{ .MediaType }})</li>
{{- else -}}
<li>No resources found in this page bundle</li>
{{- end -}}
</ul>
</div>
{{- else -}}
{{- /* Parse the CSV content */ -}}
{{- $csvData := $resource.Content | transform.Unmarshal (dict "delimiter" $delimiter) -}}
{{- /* Find the image column index if img_field is specified */ -}}
{{- $imgColIndex := -1 -}}
{{- if and $img_field $hasHeaderRow -}}
{{- $headerRow := index $csvData 0 -}}
{{- range $index, $value := $headerRow -}}
{{- if eq $value $img_field -}}
{{- $imgColIndex = $index -}}
{{- end -}}
{{- end -}}
{{- end -}}
{{- /* Create the table */ -}}
<table {{ with $id }}id="{{ . }}"{{ end }} {{ with $class }}class="{{ . }}"{{ end }}>
{{- with $caption -}}
<caption>{{ . }}</caption>
{{- end -}}
{{- if $hasHeaderRow -}}
{{- $headerRow := index $csvData 0 -}}
{{- /* Remove the img_field from header if img_field_raw is false */ -}}
{{- if and (eq $img_field_raw "false") $img_field (ne $imgColIndex -1) -}}
{{- $newHeaderRow := slice -}}
{{- range $index, $value := $headerRow -}}
{{- if ne $index $imgColIndex -}}
{{- $newHeaderRow = $newHeaderRow | append $value -}}
{{- end -}}
{{- end -}}
{{- $headerRow = $newHeaderRow -}}
{{- end -}}
{{- $rows := after 1 $csvData -}}
{{- /* Add image column to header */ -}}
{{- if $img_field -}}
{{- $headerRow = (slice (printf "%s-img-rendered" $img_field)) | append $headerRow -}}
{{- end -}}
<thead>
<tr>
{{- range $headerRow -}}
<th>{{ . | markdownify }}</th>
{{- end -}}
</tr>
</thead>
<tbody>
{{- range $rows -}}
<tr>
{{- /* Add image column first */ -}}
{{- if and $img_field (ne $imgColIndex -1) -}}
<td>
{{- $imgName := index . $imgColIndex -}}
{{- $imgSrc := printf "%s/%s.%s" (strings.TrimSuffix "/" $img_path) $imgName $img_format -}}
<img src="{{ $imgSrc }}" alt="{{ $imgName }}" loading="lazy">
</td>
{{- end -}}
{{- /* Add all other columns */ -}}
{{- range $index, $value := . -}}
{{- if or (eq $img_field_raw "true") (ne $index $imgColIndex) -}}
<td>
{{- if and (eq $index $imgColIndex) $img_path -}}
{{- /* Show the original value */ -}}
{{- $value | markdownify -}}
{{- else -}}
{{- $value | markdownify -}}
{{- end -}}
</td>
{{- end -}}
{{- end -}}
</tr>
{{- end -}}
</tbody>
{{- else -}}
<tbody>
{{- range $csvData -}}
<tr>
{{- /* Add image column first if img_field is specified */ -}}
{{- if and $img_field (ne $imgColIndex -1) -}}
<td>
{{- $imgName := index . $imgColIndex -}}
{{- $imgSrc := printf "%s/%s.%s" (strings.TrimSuffix "/" $img_path) $imgName $img_format -}}
<img src="{{ $imgSrc }}" alt="{{ $imgName }}" loading="lazy">
</td>
{{- end -}}
{{- /* Add all other columns */ -}}
{{- range . -}}
<td>{{ . | markdownify }}</td>
{{- end -}}
</tr>
{{- end -}}
</tbody>
{{- end -}}
</table>
{{- end -}}
We can call it with next CSV and image path, but we will explain in next sections how to get them.
Show both the rendered img and its field value.
{{< csv-to-table-imgs
path="data/aoe2techtree/02_add_languages_names/structures.csv"
img_path="/images/aoe2techtree/img/Buildings"
img_field="id"
>}}
The rendered img only. I.e. field `id` is not displayed.
Note: some images not rendered because they lack in the [`aoe2techtree/img/Units`](https://github.com/SiegeEngineers/aoe2techtree/tree/master/img/Units) folder of the repo.
{{< csv-to-table-imgs
path="data/aoe2techtree/02_add_languages_names/units.csv"
img_path="/images/aoe2techtree/img/Units"
img_field="id"
img_field_raw="false"
>}}
See it here.
Data
age-of-empires-II-api
Not an API anymore
In the age-of-empires-II-api repo we have
the structure file structures.csv.
The header (fields) and first three records (rows) are:
name, expansion, age, cost, build_time, hit_points, line_of_sight, armor, range, reload_time, attack, special
Barracks, Age of Kings, Dark, {"Wood": 175}, 50, 1200,5,0/7,,,,Garrison: 10 created units
Dock, Age of Kings, Dark, {"Wood": 150}, 35, 1800,5,0/7,,,,Garrison: 10 created units
Farm, Age of Kings, Dark, {"Wood": 60},15, 480,0, 0/0,,,,Standard = 175 Food;Horse Collar = 250 Food;Heavy Plow = 375 Food;Crop Rotation = 550 Food
Great! We don’t have to manually populate it. It’s already done.
We would like to create API calls to get the data from the age-of-empires-II-api API.
But, as specified in its disclaimer, the API is down.
This is inconvenient, but not a tragedy, we just need to get the
age-of-empires-II-api/data/
folder.
Git submodule and sparse checkout
Directory in the Hugo project
The documentation defines the Data sources as:
A data source might be a file in the
datadirectory, a global resource, a page resource, or a remote resource.
From the ebook Hugo in Action, Structure of the Hugo source folder, the data/ folder purpose:
data—Stores structured content in the form of YAML, TOML, CSV, or JSON files, which are made available as global variables throughout the website. A traditional database houses more than just web page content. There can be tables associated with structured data, which have no place in the content folder, so this folder comes in handy when we generate content from outside of Hugo and pass that information in as a JSON or a CSV file for Hugo to consume. We will read from the data folder in chapter 5.
And the api directory:
apifolder—Although not standard, we’ll create this folder to house custom APIs in chapter 11.
From the ebook Hugo in Action, Better together with page bundles:
The About page in the Acme Corporation website is the perfect page to turn into a leaf bundle. The draw.jpg image is used in the page, not anywhere else, and we should localize it to that page.
So, where to locate the CSV files?
- These local CSV files are, as said, local, they are not obtained via an API call using a Javascript file.
Thus we discard the
api/folder to locate them. - If they are meant to be used in the AOE2 cheatsheet page and nowhere else,
then these structured content files location shuld be in the leaf bundle folder
content/en/aoe2_cheatsheet/. - But I think that this data will be handy for future posts, I need them to be availables as global variable in
data/.
Add the git submodule and create the sparse checkout
Since our Hugo project is a git repository,
we can use the git submodule command to add the submodule directory data/age-of-empires-II-api/ to our main project repository.
But we don’t need the whole age-of-empires-II-api repository.
When working with large repositories, one might only need specific directories. Git’s sparse checkout command can
change the working tree from having all tracked files present to only having a subset of those files.
We can use this feature to keep only the age-of-empires-II-api/data/ directory and not the whole age-of-empires-II-api repository.
So, lets dive in!
First. Navigate to the main project root.
cd <project_root> # edit!
In following commands do not confuse:
- The
data/in our local Hugo project. - The
data/in the repo age-of-empires-II-api that we aim to clone intodata/age-of-empires-II-api/dataof our Hugo project.
Add the git submodule, create the sparse checkout regexp and enable sparse checkout.
# Add the whole repository as a git submodule into our data/ folder
git submodule add https://github.com/aalises/age-of-empires-II-api/ data/age-of-empires-II-api
# Create the info directory and sparse-checkout file for the submodule
mkdir -p .git/modules/data/age-of-empires-II-api/info
# Sparse-checkout regexp filters the tracked submodule content
# In this case limiting the track to the age-of-empires-II-api/data/ directory only
echo "data/*" > .git/modules/data/age-of-empires-II-api/info/sparse-checkout
# Enable sparse checkout for the submodule
git -C .git/modules/data/age-of-empires-II-api/ config core.sparseCheckout true
Now force the submodule to reset with the new sparse checkout rules.
- Option A. Either from the submodule directory
# First, navigate into the submodule directory
cd data/age-of-empires-II-api
# Reset the working tree to apply sparse checkout
git read-tree -mu HEAD
- Option B. Or from the main project directory
git submodule update --force --checkout data/age-of-empires-II-api
Let’s inspect the results.
Change directory to the submodule (cd data/age-of-empires-II-api) and run git status.
It echoes:
On branch master
Your branch is up to date with 'origin/master'.
You are in a sparse checkout with 12% of tracked files present.
nothing to commit, working tree clean
ls -la list only the data/ directory and the .git file.
Which confirms
what the 12% of tracked files present message stated,
that git sparse checkout is working – Git is only tracking and showing the files in the data directory,
ignoring the other 88% of files in the API repository.
Our tree structure is (tree -a data/):
our-hugo-project/
├── assets/
├── content/
├── data/
│ └── age-of-empires-II-api/ # The submodule
│ ├── .git
│ └── data/ # The sparse-checked-out directory
│ ├── civilizations.csv
│ ├── structures.csv
│ ├── technologies.csv
│ └── units.csv
└── [...]
Update the spared git submodule
In future, we will only update the sparse-checkout files (data/*).
One can achieve this:
- From the main project directory (A options)
- Or from the submodule directory (B options)
Via:
- Merge (A.a and B.a)
- Rebase (A.b and B.b)
- Or hard reset (B.c)
A options first step
cd <project_root> # edit!
A.a final step
git submodule update --remote --merge data/age-of-empires-II-api
A.b final step
git submodule update --remote --rebase data/age-of-empires-II-api
B options first steps
cd <project_root> # edit!
cd data/age-of-empires-II-api
git fetch origin
For the B options final steps we need to specify the origin branch we want to merge/rebase/reset-to.
Here it’s origin/master. Not origin/main.
B.a final step
git merge origin/master
B.b final step
git rebase origin/master
B.c final step
# ⚠️ Warning: This will discard any local changes you've made in the submodule.
git reset --hard origin/master
Finally, no matter which option we applied, let’s find out if the submodule is up to date.
cd <project_root> # edit!
cd data/age-of-empires-II-api
git status
aoe2techtree
We need now to focus on the icons that represent the structures (buildings) and units.
A rundementary approach would be:
- Download as many icons as possible, for example the AoE2 Full Pack Icons or one by one from spriters-resource.com.
- Manually tag the required icons in a CSV/JSON file.
Each unit
key(ID) borrowed from the fieldnamefrom the age-of-empires-II-api’sunits.csv, while the onlyvalueis the icon file-name (or file-path if grouped). Analogous for the structures. - Finally upload both the icons files and the structured data file to our Hugo project.
But we are lazy! Why would we spend 15 minutes on a non-automated task when we could automate the process with a script that would take much longer to write?

Civilization tree https://aoe2techtree.net/ is generated thanks to the repository aoe2techtree.
This projects shares:
- The PNG icons for the structures and units
- A JSON that contains the data of the structures and units, including the mentioned icons
Git submodule and sparse checkout
aoe2techtree JSON file
Add the git submodule, create the sparse checkout regexp and enable sparse checkout.
We would repeat the steps from previous section. So let’s automate it.
function add_sparse_submodule() {
local repositoryURL="$1"
local submodule="$2"
shift 2 # Remove first two arguments, rest are patterns
# Add submodule
git submodule add "$repositoryURL" "$submodule"
# Create sparse checkout config
local sparseCheckoutDir=".git/modules/${submodule}/info"
local sparseCheckoutFile="${sparseCheckoutDir}/sparse-checkout"
mkdir -p "$sparseCheckoutDir"
# Loop through remaining arguments (patterns)
for pattern in "$@"; do
echo "$pattern" >> "$sparseCheckoutFile"
done
# Enable sparse checkout
git -C $(dirname "$sparseCheckoutDir") config core.sparseCheckout true
# Apply sparse checkout
git submodule update --force --checkout "$submodule"
# Check
cd "$submodule"
git status
tree -a .
cd - > /dev/null # Return to original directory
}
Call it
# Navigate to the main Hugo project directory
cd <project_root> # edit!
# Call
add_sparse_submodule \
"https://github.com/SiegeEngineers/aoe2techtree/" \
"data/aoe2techtree" \
"data/data.json" \
"data/locales/en/strings.json"
It echoes the Git status
HEAD detached at b265c39
You are in a sparse checkout with 1% of tracked files present.
nothing to commit, working tree clean
And the structure of files
> tree -a data/aoe2techtree
data/aoe2techtree
├── data
│ ├── data.json
│ └── locales
│ └── en
│ └── strings.json
└── .git
aoe2techtree images
We could repeat previous steps with the images of the aoe2techtree repo, but now in the assets/ directory.
Structure of the Hugo source folder
in the ebook Hugo in Action states that:
assets folder—
Places images, JavaScript, and CSS files as unprocessed source code to be consumed globally from the website.
This folder allows us to process these files during compilation.
Hugo can resize images, bundle and minify JavaScript files, and convert SCSS to CSS via its asset pipeline (Hugo Pipes).
Hmmm…I think we don’t want to process these icons at all. Maybe the static/ folder? Since it’s reserved for our static content.
static—Stores static content like fonts or PDF files. Hugo copies this content as is to the output directory.
In summary,
static/for files served directly at site root (yoursite.com/images/unit.png)assets/if processed by Hugo (resizing, optimization, etc.)
Another valid path is our local bundle (content/en/aoe2_custom_cheatsheet/images), if we don’t aim to use them in other bundles (not to be consumed globally).
In these cases the sparse-checkout regular expression should filter img/Units/
and img/Buildings/ only.
Well, the resource icons (food, stone,…) might be handy too.
…Actually the img/ folder is about 2 MB, the project can handle it easily.
I choose global consumption in static/images/.
But do not execute next, we already have a Git submodule to that repository.
# Navigate to project root
cd <project_root>
# Do NOT run next
add_sparse_submodule \
"https://github.com/SiegeEngineers/aoe2techtree/" \ # !!
"static/images/aoe2techtree" \
"img/Units/*.png" \
"img/Buildings/*.png" \
"img/*.png"
Instead
mkdir -p static/images/
cd static/images/
git clone https://github.com/SiegeEngineers/aoe2techtree.git
# Remove all files and dirs except for the "img" folder
cd aoe2techtree \
&& find . -mindepth 1 -not -path './img' -not -path './img/*' -exec rm -rf {} +
Let’s check we can render images under static.
 shows:

Study the structured data
Vim
Open data.json with Vim or NeoVim
vim data/aoe2techtree/data/data.json
Set the foldmethod to syntax and enough fold-columns.
:set foldmethod=syntax foldcolumn=9
That is:
- Press
Escto go to normal mode - Type the command above. You notice that once typed the first char (the
:colon), a command bar appears, that’s intended. - Press
Enter - Wait a few seconds
Fold it all in Vim with the shortcut zM and unfold the top level with za.
You will see next. Highlighted lines are folded and their sing-column on the left show the + sign (or │+, ││+, etc.).
- 0 {
│+ 1 "age_names": {
│+ 2 "civ_helptexts": {
│+ 3 "civ_names": {
│+ 4 "data": {
│+ 5 "tech_tree_strings": {
│+ 6 "techtrees": {
│ 7 }
Move your cursor to the "data" object and unfold it with za.
- 4 {
│+ 3 "age_names": {
│+ 2 "civ_helptexts": {
│+ 1 "civ_names": {
│- 0 "data": {
││+ 1 "buildings": {
││+ 2 "node_types": {
││+ 3 "techs": {
││+ 4 "unit_upgrades": {
││+ 5 "units": {
││ 6 },
│+ 7 "tech_tree_strings": {
│+ 8 "techtrees": {
│ 9 }
Navigate to the "buildings" object and unfold it with za.
Then move to the first element, the "12" and unscroll it too.
It’s displayed like next, though I edited it a bit for clarity.
[...]represent omitted lines.- Thus, some line numbers [relative to the line of the cursor] are shown as
... - The highlighted lines are now only for the folded ones inside the
"buildings"object, to keep focus.
- 6 {
│+ 5 "age_names": {
│+ 4 "civ_helptexts": {
│+ 3 "civ_names": {
│- 2 "data": {
││- 1 "buildings": {
│││- 0 "12": {
││││ 1 "AccuracyPercent": 0,
││││+ 2 "Armours": [
││││ 3 "Attack": 0,
││││ 4 "Attacks": [],
││││+ 5 "Cost": {
││││ 6 "GarrisonCapacity": 10,
││││ 7 "HP": 1200,
││││ 8 "ID": 12,
││││ 9 "LanguageHelpId": 26135,
││││ 10 "LanguageNameId": 5135,
││││ 11 "LineOfSight": 6,
││││ 12 "MeleeArmor": 0,
││││ 13 "MinRange": 0,
││││ 14 "PierceArmor": 7,
││││ 15 "Range": 0,
││││ 16 "ReloadTime": 0,
││││ 17 "TrainTime": 50,
││││ 18 "internal_name": "Barracks Age1"
││││ 19 },
│││+ 20 "45": {
│││+ 21 "49": {
│││+ .. [...]
│││ .. },
││+ .. "node_types": {
││+ .. "techs": {
││+ .. "unit_upgrades": {
││+ .. "units": {
││ .. },
│+ .. "tech_tree_strings": {
│+ .. "techtrees": {
│ .. }
We only aim to get for each building its icon image. For the barracks we can already get it:
- The
"internal_name"field is"Barracks Age1". - The
"12"in.data.buildings["12"]acts as an ID of icons, theimg/Buildings/12.pngdisplayed below. - It might seen redudant, but
.data.buildings["12"]has the.data.buildings["12"].IDwith value12.

Sidenote. jsonpath.nvim is a Vim plugin that sends to clipboard the JSON path where the cursor is. Watch its showcasting, as well as many other plugin features, in my vim-plugins-screenshots repo.
The jq command
We overviewed the AOE2 buildings, lets inspect now the units.
Vim is awesome, but to avoid repetitive tools lets give a chance to the jq command.
Get the keys of the "units" object.
cd data/aoe2techtree/data/
jq -r '.data.units | keys[]' data.json # unsorted keys
jq -r '.data.units | keys | map(tonumber) | sort | map(tostring)[]' data.json
The first one is "4". The respective JSON object is returned via:
jq '.data.units["4"]' data.json
Note, to get the n-th value simply apply next syntax, no need to get and sort all the keys initally. [0] means the first element.
jq '.data.units | to_entries | .[0] | .value' data.json
Both last commands ouput the same result.
.data.units["4"] - Click to expand 📜
{
"AccuracyPercent": 80,
"Armours": [
{
"Amount": 0,
"Class": 4
},
{
"Amount": 0,
"Class": 15
},
{
"Amount": 0,
"Class": 3
},
{
"Amount": 0,
"Class": 31
}
],
"Attack": 4,
"AttackDelaySeconds": 0.35,
"Attacks": [
{
"Amount": 3,
"Class": 27
},
{
"Amount": 0,
"Class": 21
},
{
"Amount": 4,
"Class": 3
},
{
"Amount": 0,
"Class": 17
},
{
"Amount": 0,
"Class": 13
}
],
"BlastWidth": 0,
"ChargeEvent": 0,
"ChargeType": 0,
"Cost": {
"Gold": 45,
"Wood": 25
},
"FrameDelay": 15,
"GarrisonCapacity": 0,
"HP": 30,
"ID": 4,
"LanguageHelpId": 26083,
"LanguageNameId": 5083,
"LineOfSight": 6,
"MaxCharge": 0,
"MeleeArmor": 0,
"MinRange": 0,
"PierceArmor": 0,
"Range": 4,
"RechargeRate": 0,
"ReloadTime": 2,
"Speed": 0.96,
"TrainTime": 35,
"Trait": 0,
"TraitPiece": 0,
"internal_name": "ARCHR"
}
Therefore,
- The
"internal_name"values"ARCHR". - The
"4"ID refers to theimg/Units/4.pngbelow. - This number appears both in the JSON path
.data.units["4"]and in the value of.data.units["4"].ID.

Merge the structured data
Add an ID field to age-of-empires-II-api
Add an unique integer identifier field to a CSV file.
add_id_column() {
local input_file="${1:-input.csv}"
local output_file="${2:-output.csv}"
local header_bool="${3:-true}"
# Create a folder to store the processed data
mkdir -p $(dirname "${output_file}")
if [[ "$header_bool" == true ]]; then
# Has header: add "ID" as first column and number from 1 below header
awk -v header=1 'BEGIN {FS=OFS=","}
NR==1 {print "ID", $0; next}
{print NR-1, $0}
' "$input_file" > "$output_file"
else
# No header: just add numbered ID starting at 1 for all rows
awk 'BEGIN {FS=OFS=","}
{print NR, $0}
' "$input_file" > "$output_file"
fi
}
# Navigate to project root
cd <project_root>
# Original data dir
aoe2apiDir="data/age-of-empires-II-api/data"
# Processed data dir
bundleDir="content/en/aoe2_cheatsheet"
processedDir="${bundleDir}/data/aoe2api/01_id_numeric"
# Add ID to units
input_file="${aoe2apiDir}/units.csv"
output_file="${processedDir}/units.csv"
add_id_column "${input_file}" "${output_file}"
# Add ID to structures
input_file="${aoe2apiDir}/structures.csv"
output_file="${processedDir}/structures.csv"
add_id_column "${input_file}" "${output_file}"
Notice the new first field ID.
1> head "${processedDir}/units.csv"
2ID,name, description, expansion, age, [...]
31,Archer, Quick and light. Weak at close range; excels at battle from distance, Age of Kings, [...]
42,Crossbowman,Upgraded archer, Age of Kings, [...]
53,Arbalest,Upgraded crossbowman, Age of Kings, [...]
And analogous for the structures.
Get the unique names
Lets focus on how to get the unique age-of-empires-II-api-names.
The unique identifier was not name.
E.g. "Eagle Warrior" is a name-value duplicated in
units.csv:
10Eagle Warrior,[...], Barracks, {"info":"1 Unit free at the start of the game for Aztecs and Mayans"}, 0, 2, 0, 1.1, 6, 50, 0, 4, 0/2,+8 monks;+3 siege,,,,
11Eagle Warrior,[...], Barracks, {"Food": 20;"Gold": 50}, 35, 2, 0, 1.1, 6, 50, 0, 7, 0/2,+8 monks;+3 siege;+2 cavalry;+1 ship/camel,,,,For AOE2 units, we can run next shell chunk. It applies basic CSV processing,
cut -d',' -f1,2to get the first column (id) and the second column (names)sortto both sort by$field_uniqueand make itunique removing duplicated rows (lines with same value in this field)tail -n +2to remove the first line, the CSV header
function getUniqueNames() {
# Set default values
local input_file=${1:-file.csv}
local output_file=${2:-names_not_duplicated.csv}
local field_numbers=${3:-1,2} # Fields to output
local field_unique=${4:-2} # Field for uniqueness
# Create a folder to store the processed data
mkdir -p $(dirname "${output_file}")
# Clear output file if it exists
[ -f "$output_file" ] && \rm "$output_file"
# Get header row
new_header=$(head -n 1 "${input_file}" | cut -d',' -f"${field_numbers}")
# Create temp file
tmp_file=$(mktemp)
# Delete header
cp "$input_file" "$tmp_file"
sed -i '1d' "$tmp_file"
# Get data rows, keep both fields, then sort by the unique field and remove duplicates
cat "$tmp_file" | \
cut -d',' -f"${field_numbers}" | \
sort -t',' -k"${field_unique}" -u >> "$output_file"
# Add new header
sed -i "1i\\$new_header" "$output_file"
}
# Navigate to project root
cd <project_root>
# Original data dir
bundleDir="content/en/aoe2_cheatsheet"
originalDir="${bundleDir}/data/aoe2api/01_id_numeric"
# Processed data dir
processedDir="${bundleDir}/data/aoe2api/02_names_not_duplicated"
# Get unique-sorted names of units
input_file="${originalDir}/units.csv"
output_file="${processedDir}/units.csv"
getUniqueNames "${input_file}" "${output_file}"
# Get unique-sorted names of structures
input_file="${originalDir}/structures.csv"
output_file="${processedDir}/structures.csv"
getUniqueNames "${input_file}" "${output_file}"
Results:
> head "${processedDir}/units.csv"
ID,name
3,Arbalest
1,Archer
54,Battering Ram
69,Berserk
50,Bombard Cannon
59,Camel
24,Cannon Galleon
55,Capped Ram
71,Cataphract
> head "${processedDir}/structures.csv"
ID,name
10,Archery Range
1,Barracks
12,Blacksmith
58,Bombard Tower
24,Castle
2,Dock
3,Farm
4,Fish Trap
56,Fortified Wall
Simplify the aoe2techtree data
We need a JSON that collects from all the units next:
- The
"internal_name"field. - The
"ID"field.
Another for the buildings too.
jq in a zsh script is powerful enough to achieve this.
Clone the Hugo_AOE2_post_aux repository created expressly for current Hugo post.
scriptDir="$HOME/Downloads/Hugo_AOE2_post_aux"
git clone https://github.com/JuanMarinero/Hugo_AOE2_post_aux.git "$scriptDir"
Create a directory for the processed data.
# Navigate to project root
cd <project_root>
# Processed data dir
bundleDir="content/en/aoe2_cheatsheet"
processedDir="${bundleDir}/data/aoe2techtree/01_names_icons_only"
mkdir -p "${processedDir}"
Run the script.
# Make the script executable
scriptFile="${scriptDir}/source/aoe2techtreeGetDataIcons.sh"
chmod +x "${scriptFile}"
# Path to original data
aoe2techtreeData="data/aoe2techtree/data/data.json"
# Get name-icon data for units and buildings
source "${scriptFile}" "${aoe2techtreeData}" "${processedDir}/units.csv"
source "${scriptFile}" "${aoe2techtreeData}" "${processedDir}/structures.csv" ".data.buildings"
Results:
> head "${processedDir}/units.csv"
id, internal_name, language_name_id
1001, ORGAN, 5129
1003, EORGAN, 5130
1004, CARAV, 5132
1006, CARAV, 5133
> head "${processedDir}/structures.csv"
id, internal_name, language_name_id
101, STBL, 5171
1021, FEITO, 5159
103, BLAC, 5131
Get the language names
We wil get the aoe2techtree-language_names.
Create a Python virtual environment outside your Hugo project.
# Navigate to project root
cd <project_root>
# Activate the virtual environment
scriptDir="$HOME/Downloads/Hugo_AOE2_post_aux"
cd "$scriptDir"
python3 -m venv venv
source venv/bin/activate
pip install -r requirements.txt
# Return to project root
cd -
Convert aoe2techtree-language_names data to CSV.
# Assign the script to a variable
scriptFile="${scriptDir}/source/json2csv.py"
# Call it
bundleDirData="content/en/aoe2_cheatsheet/data/aoe2techtree"
csvMergedLanguageNames="${bundleDirData}/language_names.csv"
json="data/aoe2techtree/data/locales/en/strings.json"
columns=("ID" "language_name")
python "$scriptFile" --json-path "$json" --csv-path "$csvMergedLanguageNames" --columns "${columns[@]}"
head "$csvMergedLanguageNames"
Prints the first records:
ID,language_name
1,
1001,Age of Empires II
4201,Dark Age
4202,Feudal Age
4203,Castle Age
4204,Imperial Age
5009,Steppe Lancer
5010,Elite Steppe Lancer
5033,Composite Bowman
Next adds the language_name field to new units and structures CSV files.
# Assign the script to a variable
scriptFile="${scriptDir}/source/merge_csv_files.py"
# Call it
bundleDirData="content/en/aoe2_cheatsheet/data/aoe2techtree"
csv1Dir="${bundleDirData}/01_names_icons_only"
csv2="$csvMergedLanguageNames" # output of json2csv
resultDir="${bundleDirData}/02_add_languages_names"
mkdir -p "$resultDir"
csvs=("units" "structures")
for csv in "${csvs[@]}"; do
csv1="${csv1Dir}/${csv}.csv"
csvMerged="${resultDir}/${csv}.csv"
python "$scriptFile" \
--csv1 "$csv1" \
--csv2 "$csv2" \
--output "$csvMerged" \
--csv1-field "language_name_id" \
--csv2-field "ID"
done
The units and structures outputs are the respective dataframe heads:
id internal_name language_name_id language_name
1001 ORGAN 5129 Organ Gun
1003 EORGAN 5130 Elite Organ Gun
1004 CARAV 5132 Caravel
1006 CARAV 5133 Elite Caravel
1007 CAMAR 5134 Camel Archer
id internal_name language_name_id language_name
101 STBL 5171 Stable
1021 FEITO 5159 Feitoria
103 BLAC 5131 Blacksmith
104 CRCH 5138 Monastery
109 RTWC 5164 Town Center
Notice that the default merge (--join-type flag) is left,
thus we execute a code alike pd.merge(df1, df2, [...], how='left').
The reason is that we want to keep the original data no matter if it lacks the repsective language_name.
Luckily, both script echo that there are no rows with null values found. This will simplify the next step.
Linked data between API-s
The unique names of AOE2 units are in a subfolder of content/en/aoe2_cheatsheet/data/, specifically:
aoe2techtree/02_add_languages_names/units.csvfor the aoe2techtree with fieldsid,internal_name,language_name_idandlanguage_nameaoe2api/02_names_not_duplicated/units.csvfor the aoe2api with fieldsIDandname
We must find out how to link them.
For buildings/structures it’s the same respective directory. The corresponding JSON files basename is here structures.json.
Activate your Python virtual environment
# Navigate to project root
cd <project_root>
# Navigate to venv
scriptDir="$HOME/Downloads/Hugo_AOE2_post_aux"
cd "$scriptDir"
# Source
source venv/bin/activate
# Assign the script to a variable
scriptFile="${scriptDir}/source/fuzzymerge.py"
# Return to project root
cd -
Run the fuzzy merge code.
bundleDirData="content/en/aoe2_cheatsheet/data"
subfolders=("02_names_not_duplicated" "02_add_languages_names")
resultDir="${bundleDirData}/aoe2api-aoe2techtree/01_fuzzymerge"
mkdir -p "$resultDir"
csvs=("units" "structures")
fieldsSuffix=("aoe2api" "aoe2techtree")
for csv in "${csvs[@]}"; do
csv1="${bundleDirData}/${fieldsSuffix[1]}/${subfolders[1]}/${csv}.csv"
csv2="${bundleDirData}/${fieldsSuffix[2]}/${subfolders[2]}/${csv}.csv"
results="${resultDir}/${csv}.csv"
python "$scriptFile" \
--csv1 "$csv1" \
--csv2 "$csv2" \
--csv1-id-col "ID" \
--csv2-id-col "language_name_id" \
--csv1-name-col "name" \
--csv2-name-col "language_name" \
--csv1-field-suffix "${fieldsSuffix[1]}" \
--csv2-field-suffix "${fieldsSuffix[2]}" \
--output "$results"
done
Inspect the worst matches in-between the name_aoe2api and language_name_aoe2techtree,
i.e. the lowest values in the match score column.
E.g. for buildings:
> { head -n 1 "$results"; tail -n 10 "$results"; } | column -t -s,
name_aoe2api lang[...]_aoe2techtree ID_aoe2api lang[...]_aoe2techtree match_score
Gate Palisade Gate 53 5186 90
Fortified Wall Fortified Church 56 5038 74
Keep Krepost 59 5349 68
Castle Pasture 24 5895 62
Fish Trap Feitoria 4 5159 59
Farm Folwark 3 5581 55
Castle Mule Cart 24 5045 54
Guard Tower Harbor 57 5249 47
Dock Donjon 2 5544 45
Barracks Caravanserai 1 5440 45
Notes:
- Shrunk header for display. The column names are
name_aoe2api,language_name_aoe2techtree,ID_aoe2api,language_name_id_aoe2techtreeandmatch_score. - The fields are self-explanatory, except the
match_score. - The name-ish columns are consequitiv (the two on the left) to quickly spot the imperfect matches by eye.
- The higher match score, the better. We can edit the minimum value in the call with the
--thresholdflag from 0 (default) to 100.
Can this script be called in whatever two CSV files we want? No, each CSV must have:
- An identifier field, for later unique reference.
- And two string columns for the fuzzy match.
What did this script perform?
- It looped each
--name-colitem in the--csv2, in this case eachlanguage_namevalue [of each row] of the AOE2TechTree CSV (encapsulating units or buildings). - Since we previously sorted this data alphabetically, then the result loop will also be in the alphabetical order of this column.
- We choose the AOE2TechTree data as
--csv2because we want to find a match for each of its icons in the AOE2API data, and not necessary vice versa. - In each looped
fuzzywuzzytries to find its best fuzzy match in the columnnameof the other CSV (--csv1), the AOE2API data. - Each iteration finishes recording the best result and correspondings pairs of ID-s and name-s.
- Finally, some rows of the AOE2API CSV (
--csv1) might have not been best matched in the loop. We append them to the end of the final CSV. With no values for the respectives AOE2API ID-s and names. No match score eiter. - This no matched rows are kept for consistency with the original CSVs. And because in later data mining steps we might want to work with them. As we will see, the fuzzy match results are far from perfect.
Merge the icons
Wrapping up, in content/en/aoe2_cheatsheet/data/ we have:
aoe2techtree/02_add_languages_names/<units|structures>.csv-fields areid,internal_name,language_name_idandlanguage_nameaoe2api-aoe2techtree/01_fuzzymerge/<units|structures>.csvwith headername_aoe2api,language_name_aoe2techtree,ID_aoe2api,language_name_id_aoe2techtreeandmatch_score.
With real data is easier to understand. Lets observe a single record, the second for example:
CSV_display_vert(){
local csv="$1"
local row="$2"
paste -d'\t' <(head -n1 "$csv" | tr ',' '\n') <(sed -n "$row"p "$csv" | tr ',' '\n') | column -ts $'\t'
}
> CSV_display_vert "${bundleDirData}/aoe2techtree/02_add_languages_names/structures.csv" 2
id 101
internal_name STBL
language_name_id 5171
language_name Stable
> CSV_display_vert "${bundleDirData}/aoe2api-aoe2techtree/01_fuzzymerge/structures.csv" 2
name_aoe2api Stable
language_name_aoe2techtree Stable
ID_aoe2api 19
language_name_id_aoe2techtree 5171
match_score 100
Remember that the id of aoe2techtree/02_add_languages_names is the key to render icons.
We shall join these datasets by:
language_name_idofaoe2techtree/02_add_languages_names- With
language_name_id_aoe2techtreeofaoe2api-aoe2techtree/01_fuzzymerge
Activate your Python virtual environment and get the script.
# Navigate to project root
cd <project_root>
# Navigate to venv
scriptDir="$HOME/Downloads/Hugo_AOE2_post_aux"
cd "$scriptDir"
# Source
source venv/bin/activate
# Assign the script to a variable
scriptFile="${scriptDir}/source/merge_csv_files.py"
# Return to project root
cd -
Run next.
bundleDirData="content/en/aoe2_cheatsheet/data"
csv1Dir="${bundleDirData}/aoe2techtree/02_add_languages_names"
csv2Dir="${bundleDirData}/aoe2api-aoe2techtree/01_fuzzymerge"
resultDir="${bundleDirData}/aoe2api-aoe2techtree/02_icon_merge"
mkdir -p "$resultDir"
csvs=("units" "structures")
for csv in "${csvs[@]}"; do
csv1="${csv1Dir}/${csv}.csv"
csv2="${csv2Dir}/${csv}.csv"
csvMerged="${resultDir}/${csv}.csv"
python "$scriptFile" \
--csv1 "$csv1" \
--csv2 "$csv2" \
--csv1-field "language_name_id" \
--csv2-field "language_name_id_aoe2techtree" \
--csv1-field-remove "False" \
--csv2-field-remove "False" \
--join-type "inner" \
--output "$csvMerged"
done
For buildings we get for example next record. We keep all fields.
> CSV_display_vert "$csvMerged" 2
id 101
internal_name STBL
language_name_id 5171
language_name Stable
name_aoe2api Stable
language_name_aoe2techtree Stable
ID_aoe2api 19
language_name_id_aoe2techtree 5171
match_score 100
Now we want unique icons and sort by match score.
for csv in "${csvs[@]}"; do
csvMerged="${resultDir}/${csv}.csv"
inputFile="$csvMerged"
outputFile="${resultDir}/unique_icon/${csv}.csv"
mkdir -p "$(dirname $outputFile)"
python3 -c "
import pandas as pd;
import sys;
# Create dataframe
inputfile = sys.argv[1];
df = pd.read_csv(inputfile);
# Reorder and skip colums
# - language_name_aoe2techtree col is duplicated
# - name_aoe2api to the first column to compare with the rendered icon easily
# - language_name then to compare strings with previous column
# - ID_aoe2api and id side by side to notate ID-s of pairs to discard
df = df[['name_aoe2api', 'language_name', 'ID_aoe2api', 'id', 'match_score']]
# Sort the result by match_score descending
df.sort_values('match_score', ascending=False, inplace=True)
# Drop duplicates
df.drop_duplicates(subset=['id'], keep='first', inplace=True)
# Output
outfile = sys.argv[2];
df.to_csv(outfile, index=False)
# Print
print(df.head(10).to_string(index=False))
" $inputFile $outputFile
done
Manual matches
The above script does not give us the best possible matches.
We check it visually thanks to a custom Hugo shortcode that renders a CSV as a HTML-table and even display an image for each row. Details in previous sections:
Since the previous merged CSV is stored in
content/en/aoe2_cheatsheet/data/aoe2api-aoe2techtree/02_icon_merge/unique_icon/structures.csv,
we use the csv-to-table-imgs shortcode with the following call in a markdown:
{{< csv-to-table-imgs
path="data/aoe2api-aoe2techtree/02_icon_merge/unique_icon/structures.csv"
img_path="/images/aoe2techtree/img/Buildings"
img_field="id"
>}}
{{< csv-to-table-imgs
path="data/aoe2api-aoe2techtree/02_icon_merge/unique_icon/units.csv"
img_path="/images/aoe2techtree/img/Units"
img_field="id"
>}}
See it here.
Screenshot:
Click to expand the screenshot
Well, we will do some manual matches:
- For each row check if the icon displayed in the
ID_aoe2techtree-img-renderedcolumns makes sense with thename_aoe2apicolumn. These two are one after the other for convienience. - If the match seems wrong, then search the proper value among the
name_aoe2api-s. Find its correspondingID_aoe2apiand take a note of the new [ID_aoe2techtree,ID_aoe2api] pair.
Results. Next associated records are wrong.
| name_aoe2api | language_name | ID_aoe2api | id | match_score |
|---|---|---|---|---|
| Fortified Wall | Fortified Church | 56 | 1806 | 74 |
| Keep | Krepost | 59 | 1251 | 68 |
| Castle | Pasture | 24 | 1889 | 62 |
| Fish Trap | Feitoria | 4 | 1021 | 59 |
| Farm | Folwark | 3 | 1734 | 55 |
| Castle Mule | Cart | 24 | 1808 | 54 |
| Guard Tower | Harbor | 57 | 1189 | 47 |
| Dock | Donjon | 2 | 1665 | 45 |
| Barracks | Caravanserai | 1 | 1754 | 45 |
Thus, we must overwrite the following [ID_aoe2techtree, ID_aoe2api] pairs,
in all these cases with a NULL value since no other row of AOE2API matches the AOE2TechTree image (nor name).
| id | ID_aoe2api |
|---|---|
| 1806 | NULL |
| 1251 | NULL |
| 1889 | NULL |
| 1021 | NULL |
| 1734 | NULL |
| 1808 | NULL |
| 1189 | NULL |
| 1665 | NULL |
| 1754 | NULL |
We apply the same algorithm to the units.
Once finished pass the dict reassign_maps of new best matches to next script.
Activate your Python virtual environment and get the script.
# Navigate to project root
cd <project_root>
# Navigate to venv
scriptDir="$HOME/Downloads/Hugo_AOE2_post_aux"
cd "$scriptDir"
# Source
source venv/bin/activate
# Assign the script to a variable
scriptFile="${scriptDir}/source/get_ID_mapping.py"
# Return to project root
cd -
And run:
bundleDirData="content/en/aoe2_cheatsheet/data"
inputDir="${bundleDirData}/aoe2api-aoe2techtree/02_icon_merge"
resultDir="${bundleDirData}/aoe2api-aoe2techtree/03_ID_mapping"
mkdir -p "$resultDir"
# TODO complete units-dict
csvs=(units structures)
reassign_maps=(
'{1263: null, 1129: null, 1889: null, 873: null, 875: null, 1007: null, 1009: null, 1970: null, 1968: null, 1923: null, 1230: null, 1255: null}'
'{1806: null, 1251: null, 1889: null, 1021: null, 1734: null, 1808: null, 1189: null, 1665: null, 1754: null}'
)
for i in {1..${#csvs}}; do
csv="${csvs[$i]}"
reassign_map="${reassign_maps[$i]}"
input="${inputDir}/${csv}.csv"
result="${resultDir}/${csv}.csv"
echo "Processing $csv with reassign-map: $reassign_map"
python "$scriptFile" \
--input "$input" \
--output "$result" \
--id1-field "id" \
--id2-field "ID_aoe2api" \
--reassign-maps "$reassign_map"
done
For buildings we get for example next record. We keep all fields.
> head $result
id,ID_aoe2api
101,19
1021,
103,12
104,31
109,9
117,54
1189,
1251,
12,1
Units joining is a bit more complicated. Too many records that fuzzy match algorithm is unable to associate.
I think it’s too much for manual intervention. Therefore, we shall ignore the AOE2 units from now on. Though the remaining code chunks will act as we would still be insterested in them.
Hotkeys
Create a hotkey table
For the AOE2 Definitive Edition the default hotkey layout follows the QWERTY layout.
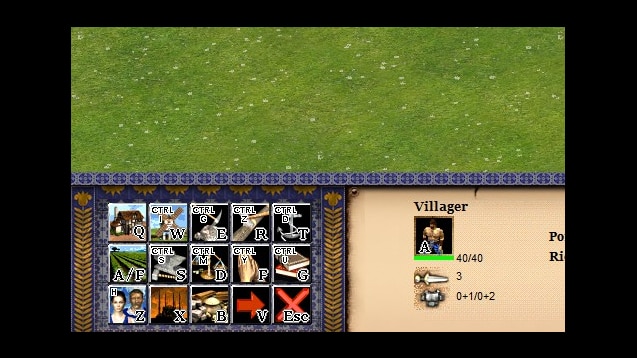
E.g. to build an structure one must:
- Select Villager/s
- Press
Qfor economic buildings,Wfor military - Press corresponding hotkey: Barracks
Q, ArcheryW,…
We will create a hotkey table only on the buildings. We had next rendered table:
Click to expand the screenshot
Well, we will do some manual matches:
- Read the name of the icon, e.g.
Stable. So we know that the first hotkey isW(military building). - Annotate the
id(theID_aoe2techtree), e.g.101 - Find out the respective hotkey. For example go to ageofempires.fandom hotkeys and look for
Stable. Thus, we next next key-value pairs:101: W + E
Write results to next CSV file.
# Navigate to project root
cd <project_root>
# Processed data dir
bundleDirData="content/en/aoe2_cheatsheet/data"
# New data dir
aoe2techtreeHotkeysDir="$bundleDirData/aoe2techtree-hotkeys/"
mkdir -p "$aoe2techtreeHotkeysDir"
# Buildings
csvFile="$aoe2techtreeHotkeysDir/structures.csv"
$EDITOR "$csvFile"
id,hotkey1,hotkey2,select
101,W,E,
103,Q,S,
104,Q,F,
235,W,F,
234,W,F,
109,Q,Z,
71,Q,Z,
621,Q,Z,
155,W,D,
117,W,D,
12,W,Q,
487,W,Z,
199,Q,Q,Fishing-ship
79,W,F,
209,Q,G,
72,W,S,
45,Q,T,
1189,Q,T,
276,Q,X,
236,W,G,
50,Q,A,
49,W,R,
562,Q,R,
598,W,A,
584,Q,E,
87,W,W,
82,W,C,
70,Q,Q,
84,Q,D,
68,Q,W,
792,W,X,
1806,W,F,
1251,W,T,
1021,Q,C,
1734,W,I,
1808,Q,R,Market
1665,W,T,
1754,W,C,
Merge
Activate your Python virtual environment and get the script.
# Navigate to project root
cd <project_root>
# Navigate to venv
scriptDir="$HOME/Downloads/Hugo_AOE2_post_aux"
cd "$scriptDir"
# Source
source venv/bin/activate
# Assign the script to a variable
scriptFile="${scriptDir}/source/merge_csv_files.py"
# Return to project root
cd -
And run:
bundleDirData="content/en/aoe2_cheatsheet/data"
csv1Dir="${bundleDirData}/aoe2api-aoe2techtree/03_ID_mapping"
csv2Dir="${bundleDirData}/aoe2techtree-hotkeys/"
resultDir="${bundleDirData}/aoe2api-aoe2techtree/04_shortcuts_merge"
mkdir -p "$resultDir"
csvs=("units" "structures")
for csv in "${csvs[@]}"; do
csv1="${csv1Dir}/${csv}.csv"
csv2="${csv2Dir}/${csv}.csv"
csvMerged="${resultDir}/${csv}.csv"
if [[ ! -e "$csv2" ]]; then
continue
fi
python "$scriptFile" \
--csv1 "$csv1" \
--csv2 "$csv2" \
--csv1-field "id" \
--csv2-field "id" \
--csv1-field-remove "False" \
--csv2-field-remove "True" \
--join-type "left" \
--output "$csvMerged"
done
The result dataframe head looks like:
id ID_aoe2api hotkey1 hotkey2 select
101 19.0 W E NaN
1021 NaN Q C NaN
103 12.0 Q S NaN
104 31.0 Q F NaN
Notice the implicit type coercion of the ID_aoe2api column because of the missing values.
Undo it:
for csv in "${csvs[@]}"; do
csvMerged="${resultDir}/${csv}.csv"
if [[ ! -e "$csvMerged" ]]; then
continue
fi
inputFile="$csvMerged"
outputFile="$csvMerged"
python3 -c "
import pandas as pd;
import sys;
# Create dataframe
inputfile = sys.argv[1];
df = pd.read_csv(inputfile);
# Nullable integer. Hold integer values alongside NA (missing values) without upcasting to float
df['ID_aoe2api'] = df['ID_aoe2api'].astype('Int64')
# Output
outfile = sys.argv[2]; df.to_csv(outfile, index=False)
# Print
print(df.head(10).to_string(index=False))
" $inputFile $outputFile
done
Now both ID columns are integers.
id ID_aoe2api hotkey1 hotkey2 select
101 19 W E NaN
1021 <NA> Q C NaN
103 12 Q S NaN
104 31 W F NaN
Preview the icons with the csv-to-table-imgs shortcode:
{{< csv-to-table-imgs
path="data/aoe2api-aoe2techtree/04_shortcuts_merge/structures.csv"
img_path="/images/aoe2techtree/img/Buildings"
img_field="id"
>}}
See it here.
Add the AOE2API fields
Previous table has:
idfrom AOE2TechTree ofaoe2api-aoe2techtreeID_aoe2apifrom AOE2API ofaoe2api-aoe2techtree- Hotkeys from
aoe2techtree-hotkeys
Lets add all the AOE2API fields:
bundleDirData="content/en/aoe2_cheatsheet/data"
csv1Dir="${bundleDirData}/aoe2api-aoe2techtree/04_shortcuts_merge"
csv2Dir="${bundleDirData}/aoe2api/01_id_numeric"
resultDir="${bundleDirData}/aoe2api-aoe2techtree/05_add_aoe2api_fields"
mkdir -p "$resultDir"
csvs=("units" "structures")
for csv in "${csvs[@]}"; do
csv1="${csv1Dir}/${csv}.csv"
csv2="${csv2Dir}/${csv}.csv"
csvMerged="${resultDir}/${csv}.csv"
if [[ ! -e "$csv1" ]]; then
continue
fi
python "$scriptFile" \
--csv1 "$csv1" \
--csv2 "$csv2" \
--csv1-field "ID_aoe2api" \
--csv2-field "ID" \
--csv1-field-remove "False" \
--csv2-field-remove "True" \
--join-type "left" \
--output "$csvMerged"
done
We can render it via:
{{< csv-to-table-imgs
path="data/aoe2api-aoe2techtree/05_add_aoe2api_fields/structures.csv"
img_path="/images/aoe2techtree/img/Buildings"
img_field="id"
>}}
See it here.
Final result
Final polished table for AOE2 structures:
- Sorted by QWERTY hotkeys and remove records with same shortcuts
- Filter AOE2API most practical fields
- Cast all float columns to integer
csv="structures.csv"
bundleDirData="content/en/aoe2_cheatsheet/data"
inputFile="${bundleDirData}/aoe2api-aoe2techtree/05_add_aoe2api_fields/${csv}"
outputFile="${bundleDirData}/aoe2api-aoe2techtree/06_filter/${csv}"
mkdir -p "$(dirname "$outputFile")"
python3 -c "
import pandas as pd
import sys
import os
# Check if input file exists
inputfile = sys.argv[1]
if not os.path.exists(inputfile):
print(f'Error: Input file {inputfile} does not exist')
sys.exit(1)
# Create dataframe
df = pd.read_csv(inputfile)
# Remove whitespace from column names
df.columns = df.columns.str.strip()
# Keep only the row with max 'ID_aoe2api' in each group of hotkey1 & hotkey2
df.dropna(subset=['hotkey1', 'hotkey2'], inplace=True)
# Get idxmax for each group, ignoring groups with all NaNs in 'ID_aoe2api'
idxmax_series = df.groupby(['hotkey1', 'hotkey2'])['ID_aoe2api'].idxmax()
# Drop NaN indices which arise if group is all NaN in 'ID_aoe2api'
idxmax_series = idxmax_series.dropna().astype(int)
# Select rows by valid indices
df_unique = df.loc[idxmax_series]
# Filter columns
cols = ['id', 'hotkey1', 'hotkey2', 'cost', 'build_time', 'hit_points', 'line_of_sight', 'armor', 'range', 'special']
df_filtered = df_unique[cols]
# Nullable integer. Hold integer values alongside NA (missing values) without upcasting to float
float_cols = df_filtered.select_dtypes(include=['float']).columns
df_filtered[float_cols] = df_filtered[float_cols].astype('Int64')
# Define sort orders
order1 = ['Q', 'W']
order2 = list(''.join(['QWERTYUIOP', 'ASDFGHJKL', 'ZXCVBNM']))
order1_map = {k: i for i, k in enumerate(order1)}
order2_map = {k: i for i, k in enumerate(order2)}
# Sort by hotkey1 (Q/W) then hotkey2 (QWERTY order)
df_sorted = df_filtered.sort_values(
by=['hotkey1', 'hotkey2'],
key=lambda col: col.map(order1_map if col.name == 'hotkey1' else order2_map).fillna(len(order2))
)
# Output
outfile = sys.argv[2]
df_sorted.to_csv(outfile, index=False)
# Print first 10 rows
print('First 10 rows of sorted data:')
print(df_sorted.head(10).to_string(index=False))
" "$inputFile" "$outputFile"
Finally replace resources words with emojis:
sed -i 's/Wood/🪵/g' "$outputFile"
sed -i 's/Stone/🪨/g' "$outputFile"
sed -i 's/Gold/🪙/g' "$outputFile"
sed -i 's/Food/🌾/g' "$outputFile"
sed -i 's/units/👥/g' "$outputFile"
sed -i 's/population/👥/g' "$outputFile"
Render it:
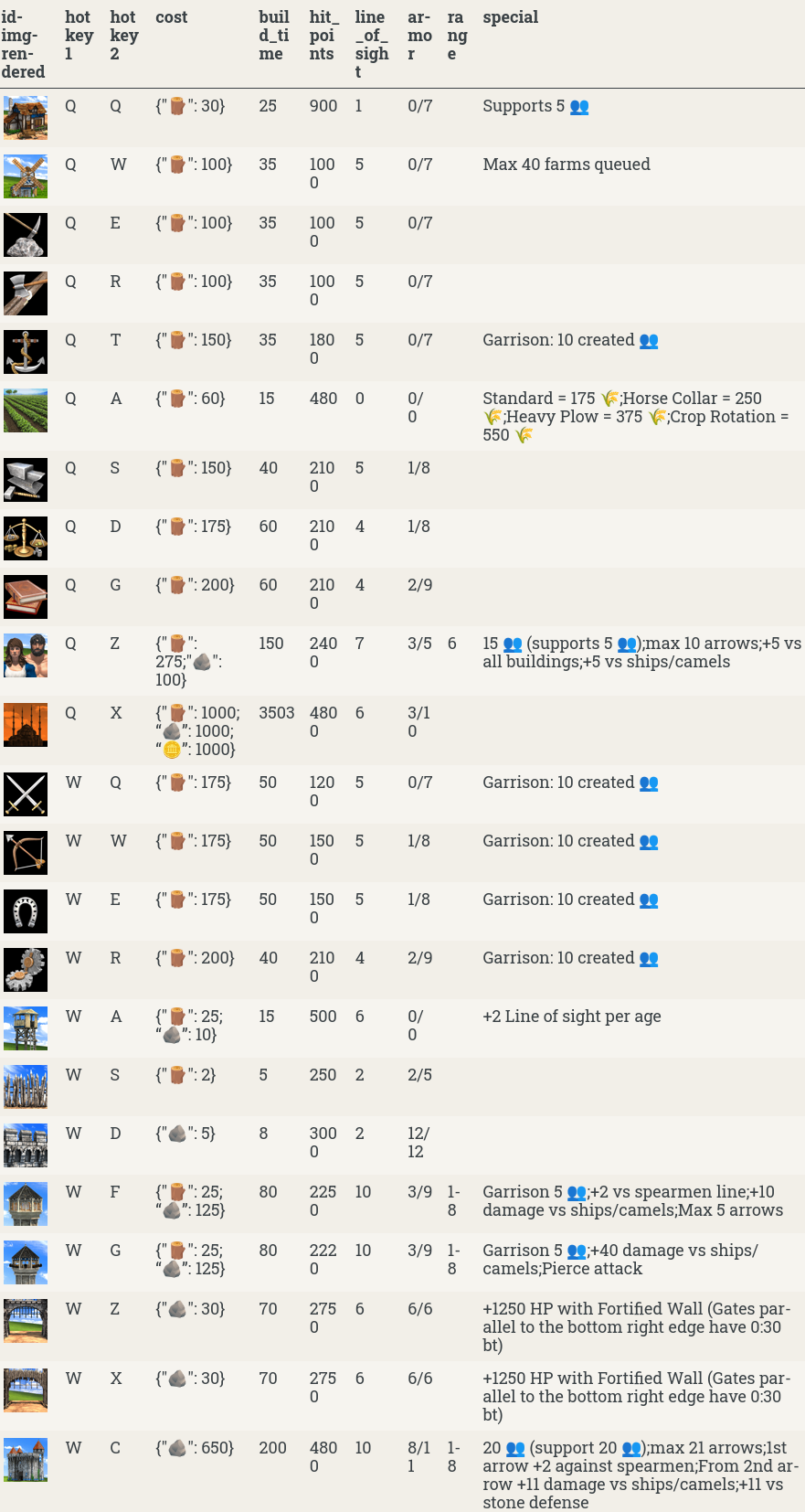
{{< csv-to-table-imgs
path="data/aoe2api-aoe2techtree/06_filter/structures.csv"
img_path="/images/aoe2techtree/img/Buildings"
img_field="id"
img_field_raw="false"
>}}
See it here.
Screenshot:
Bonus
Hugo further readings:
- Hugo in Action chapter 9, Accessing APIs to enhance functionality
AOE2 guides and cheatsheets:
Imagination is the limit
Hugo shortcode to render a table with images
csv-to-table-imgs.html is can be further improved to get features like:
- Pass width and/or height of the images to render
- Do not display every column but the ones in a list.
Hugo’s code block and
Hugo’s highlight shortcode
already accept a list of lines to highlight, e.g.
hl_lines=3 6-8. We can use their templates as reference. - Arbitray column to render the image, instead of the first one always.
Or even reconsider the whole code to render multiple images from the same CSV data:
$img_fieldas a list of columns to be rendered as image$img_pathwould be the list of each image file location in the Hugo project$img_formattheir respective formats (e.g.pngorjpg)$captionargument to stack the corresponding caption strings- Etc.
Diagrams
The Fast Castle Boom diagram is really cool. But what if I tell you that Hugo can create it too? Even much more complex diagrams. Check,
Table re-sorted or re-grouped
Our structures table displays useful information, but instead of QWERTY sorted, we might want it grouped by building’s category. Like next:
Click to expand 📜
- Resources
- Mine [shortcut, cost, time to build,…]
- Lumberjack
- Mill
- Farm
- Fishtrap
- …
- Civilian
- House
- Town center
- University
- …
- Military
- Barracks
- Archery
- Stable
- …
- Water
- Dock
- …
Focus on shortcuts
Cheatsheet for shortcuts to generate units, find idle units, military formation,…
Click to expand 📜
- Generate Civilian
- Peasent: [Icon rendered, shortcut to pick a town center and create a villager]
- Trader
- Fishship
- Generate Warrior
- Paladin-sh
- Spear
- Knight
- Archers -…
- Knights
-…
Castle
- Special
- Trebuchet Asedio -… Ships
- … Monks
- Paladin-sh
- Idle
- Civilian ,💤🪚🪵
- Warrior 💤⚔️
- Armee
- Agresion status (??)
- Passive 🕊️
- Surround watch
- Aggressive
- Formation
- fila
- cuadrado concéntrico
- difuminado
- en 2 grupos
- Misscelaneos:
- Seq. Action: Ctrl
- Circle movement 🔄
- Stop ✋